
Postgres automatic and (mostly) transparent) failover with pgpool
I have been working a lot with pgpool recently and I wanted to document my experiments in case it is helpful for others.
In this post I will document step by step how to install postgres/pgpool and how to configure pgpool to automate the failover. I will then install a graphical interface on top of pgpool (that I developed).
Intro
This post is intended as a learning material, it lists step by step how to install postgres/pgpool/repmgr. Since everything can be done at the command line, I will later expand on this set-up to do automated testing of pgpool watchdog. Please note that in my current company I deployed postgres and pgpool as docker images, either in a docker swarm or directly on the servers (i.e. using docker run to start the containers). This is all in the github repo https://github.com/saule1508/pgcluster. If you start a learning journey with pgpool and postgres, using docker can be of good help because it makes experimenting and testing very easy (you can quickly start from scratch).
I will put more emphasis on pgpool concepts or configurations that I found difficult to grasp (sometimes because they are poorly documented). For postgres and repmgr and will essentially list all the steps required to set it up but it is obviously very much recommanded to read the respective docs.
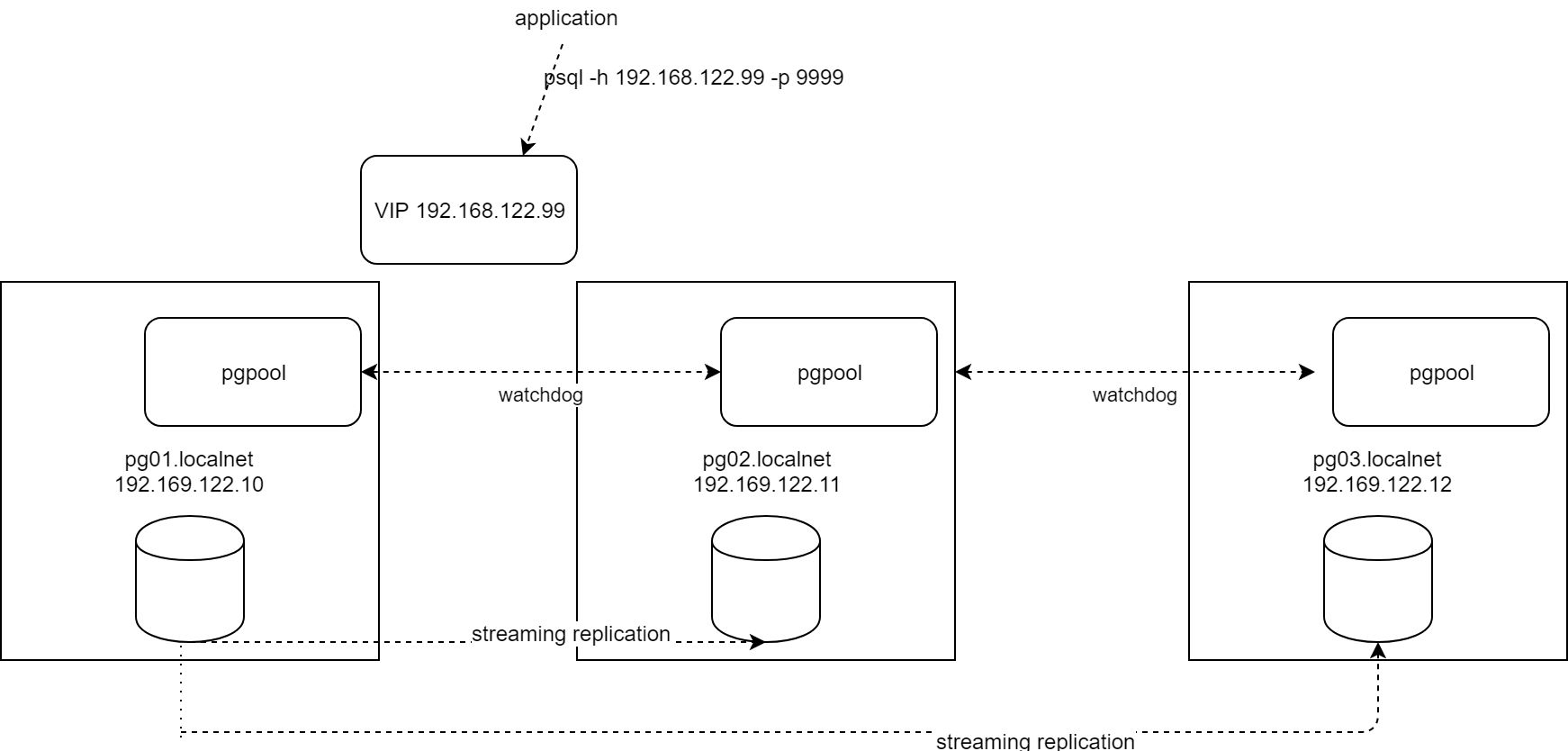
The end result is a set-up composed of 3 Centos 7.6 servers: one primary database and two stand-by databases, with one pgpool on each node made high-available with the watch-dog mode of pgpool. I use repmgr (https://repmgr.org/), not to automate the failover but because it brings well tested scripts on top of postgres replication.
NB: I am using libvirt to provision the VM (I provision one server then clone it), but you can use vagrant, virtual box, VMWare or provision the centos guests manually. If you have a linux host available then I suggest to use libvirt, I documented here a way to provision a centos guest from the command line in a few minutes: Centos guest VM with cloud-init, this is just great.
The end-result will be similar to this:
- diagram
- graphical interface
pgpool: some facts
Before building the set-up, here are some considerations on Pgpool. Pgpool is hard to learn because it can do a lot of things and the documentation is overwhelming and not always clear. There are 3 main functions that are useful, the other are more esoteric or for historic reasons (like query result caching, master-master replication,…). Pgpool has a good community and once we know it we like it
Connection caching
If you think about traditionnal connection pooling in the java world, where the webcontainer manages the connection pool and java threads borrow one connection from the pool for the time of a transaction, then you will be confused by Pgpool. Pgpool does connection caching. When application connects to Pgpool, Pgpool uses one of its child process, then create a connection to postgres and associate the postgres connection to the child process. When the application disconnects from pgpool, the postgres connection is cleaned-up (to release locks for ex.) and it is kept open, so that it remains in the cache for the next time.
If you have modern applications using connection pooling and if you have a lot of different databases or user name, then connection caching of pgpool might not be interesting and it can be disabled (parameter connection_cache=’off’)
Automated failover and (mostly) transparent
Postgres has a strong replication mechanisme (hot standby) in which a primary database streams its transaction logs (wal in postgres terminology, write-ahead-logs) and one or more standby databases receive those write-ahead-log and apply them continuously so that all changes done on the primary are replicated on the standbys. The primary database is open read-write, the stand-by databases are opened read-only. But postgres does not offer any automated way to promote a stand-by database in case of failure of the primary. Furthermore, if a stand-by database is manually promoted and become the new read-write database, all applications connected to the database must now be made aware that they must connect to a new instance.
Pgpool solve those problems, it is used on top of the postgres databases, acting as a proxy, it uses the following mechanisms to detect a failure and trigger a failover:
- health checks: pgpool connects (with user health_check_user) regularly (param health_check_period) to the databases and so is aware when a primary (or a standby) fails. After a retry period (health_check_retry_interval and health_check_retries) it will trigger a failover, which concretely mean calling a script with a number of arguments.
- Alternatively it can use the parameter failover_on_backend_error. This parameter should be off if you use health check. What failover_on_backend error means is that when Pgpool receives an error on one of the connections, it will immediately trigger a failover. So there is no retry. Furthermore is there is no activity then the failure will not be detected and the failover will not occur.
Transparent failover is achieved because clients are connecting to pgpool and not directly to postgres: if a failover happens, then pgpool knows that the primary database has changed and it will destroy then re-create all connections to postgres without any configuration needed on the client side. Of course it is not completly transparent, any statement (query or update) that was being executed will return an error.
But if pgpool is a proxy between the applications and postgres, a failure of pgpool itself would result in a lost of availability. In other words pgpool itself has become the single point of failure and of course it has a very nice mechanism that makes itself HA: the watchdog mode
pgpool watchdog mode
- watchdog adds high availability by coordinating multiple pgpool nodes (one leaded elected via consensus). The leader acquires the VIP (acquiring the VIP is done via a script using ip and arp)
- pgpool nodes communicates via tcp port 9000 (ADD_NODE command, etc.)
- watchdog uses a heartbeat mechanism (optionally it can use a query mechanism instead): a “lifecheck process” sends and receives data over UDP (port 9694) to check the availability of other nodes
pgpool management protocol
pcp exposes its function through pcp (pgpool control protocol) on tcp port 9898. This requires a user (choose postgres) and a password (the combination must be stored in a file /home/postgres/.pcppass), so that the linux user postgres can use pcp_attach_node, pcp_recovery_node, etc…
1. Create first server with centos 7, postgres, repmgr and pgpool
The installation of the centos 7 guest is described in the link http://saule1508.github.io/libvirt-centos-cloud-image.
It needs a file system /u01 for the database (the DB will be in /u01/pg11/data), a file system /u02 for the archived write ahead logs (wal) and the backups (/u02/archive and /u02/backup). I create a user postgres with uid 50010 (arbitrary id, does not matter but it is better to have the same id on all servers). The user must be created before the rpm is installed.
1.2 Postgres
# as user root
MAJORVER=11
MINORVER=2
yum update -y
# install some useful packages
yum install -y epel-release libxslt sudo openssh-server openssh-clients jq passwd rsync iproute python-setuptools hostname inotify-tools yum-utils which sudo vi firewalld
# create user postgres before installing postgres rpm, because I want to fix the uid
useradd -u 50010 postgres
# set a password
passwd postgres
# So that postgres can become root without password, I add it in sudoers
echo "postgres ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/postgres
# install postgres release rpm, this will add a file /etc/yum.repos.d/pgdg-11-centos.repo
yum install -y https://download.postgresql.org/pub/repos/yum/${MAJORVER}/redhat/rhel-7-x86_64/pgdg-centos${MAJORVER}-${MAJORVER}-${MINORVER}.noarch.rpm
# with the repo added (repo is called pgdg11), ww can install postgres
# NB: postgres is also available from Centos base repos, but we want the latest version (11)
yum install -y postgresql${MAJORVER}-${MAJORVER}.${MINORVER} postgresql${MAJORVER}-server-${MAJORVER}.${MINORVER} postgresql${MAJORVER}-contrib-${MAJORVER}.${MINORVER}
# verify
yum list installed postgresql*
I want to store the postgres database in /u01/pg11/data (non-default location), I want to have the archived wal in /u02/archive and the backup in /u02/backup
mkdir -p /u01/pg${MAJORVER}/data /u02/archive /u02/backup
chown postgres:postgres /u01/pg${MAJORVER}/data /u02/archive /u02/backup
chmod 700 /u01/pg${MAJORVER}/data /u02/archive
The environment variable PGDATA is important: it points to the database location. We need to change it from the rpm default (which is /var/lib/pgsql/11/data) to the new location /u01/pg11/data.
export PGDATA=/u01/pg${MAJORVER}/data
# add the binaries in the path of all users
echo "export PATH=\$PATH:/usr/pgsql-${MAJORVER}/bin" > /etc/profile.d/postgres.sh
# source /etc/profile in bashrc of user postgres, make sure that PGDATA is defined and also PGVER so that we
# can use PGVER in later scripts
echo "[ -f /etc/profile ] && source /etc/profile" >> /home/postgres/.bashrc
echo "export PGDATA=/u01/pg${MAJORVER}/data" >> /home/postgres/.bashrc
echo "export PGVER=${MAJORVER}" >> /home/postgres/.bashrc
We need a systemd unit file for postgres, so that it is started automatically when we boot the server (see https://www.postgresql.org/docs/11/server-start.html)
cat <<EOF > /etc/systemd/system/postgresql.service
[Unit]
Description=PostgreSQL database server
Documentation=man:postgres(1)
[Service]
Type=notify
User=postgres
ExecStart=/usr/pgsql-11/bin/postgres -D /u01/pg11/data
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
KillSignal=SIGINT
TimeoutSec=0
[Install]
WantedBy=multi-user.target
EOF
enable the unit but don’t start it yet
sudo systemctl enable postgresql
Now we can init the database, as user postgres
su - postgres
# check that PGDATA and the PATH are correct
echo $PGDATA
echo $PATH
pg_ctl -D ${PGDATA} initdb -o "--auth=trust --encoding=UTF8 --locale='en_US.UTF8'"
postgres configuration parameters are in $PGDATA/postgres.conf, I prefer not to change this file but include an additional file from the config.d directory and override some of the defaults parameter. I add the line “include_dir=’conf.d’” at the end of postgresql.conf and then I add custom configurations in conf.d
# as user postgres
mkdir $PGDATA/conf.d
echo "include_dir = 'conf.d'" >> $PGDATA/postgresql.conf
# now let's add some config in this conf.d directory
cat <<EOF > $PGDATA/conf.d/custom.conf
log_destination = 'syslog,csvlog'
logging_collector = on
# better to put the logs outside PGDATA so they are not included in the base_backup
log_directory = '/var/log/postgres'
log_filename = 'postgresql-%Y-%m-%d.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
# These are relevant when logging to syslog (if wanted, change log_destination to 'csvlog,syslog')
log_min_duration_statement=-1
log_duration = on
log_line_prefix='%m %c %u - '
log_statement = 'all'
log_connections = on
log_disconnections = on
log_checkpoints = on
log_timezone = 'Europe/Brussels'
# up to 30% of RAM. Too high is not good.
shared_buffers = 512MB
#checkpoint at least every 15min
checkpoint_timeout = 15min
#if possible, be more restrictive
listen_addresses='*'
#for standby
max_replication_slots = 5
archive_mode = on
archive_command = '/opt/postgres/scripts/archive.sh %p %f'
# archive_command = '/bin/true'
wal_level = replica
max_wal_senders = 5
hot_standby = on
hot_standby_feedback = on
# for pg_rewind
wal_log_hints=true
EOF
I prefer to put the logs outside PGDATA, otherwise a backup might become very big just because of the logs. So we must create the directory
sudo mkdir /var/log/postgres
sudo chown postgres:postgres /var/log/postgres
As you can see I use the script /opt/postgres/scripts/archive.sh as archive command, this needs to be created
sudo mkdir -p /opt/postgres/scripts
sudo chown -R postgres:postgres /opt/postgres
content of script /opt/postgres/scripts/archive.sh
#!/bin/bash
LOGFILE=/var/log/postgres/archive.log
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
echo "archiving $1 to /u02/archive/$2"
cp $1 /u02/archive/$2
exit $?
make sure it is executable
chmod +x /opt/postgres/scripts/archive.sh
⚠️: When archive mode is on, you must clean the directory where archived wal’s are copied. Usually via a backup script that takes a backup and then remove archived wal older than the backup
Now let’s create a database and a user
sudo systemctl start postgresql
# verify
sudo systemctl status postgresql
psql -U postgres postgres
at the psql prompt, create a database (my database is called critlib), then quit
create database critlib encoding 'UTF8' LC_COLLATE='en_US.UTF8';
\q
now reconnect to the newly create database and create two users (cl_owner and cl_user)
psql -U postgres critlib
create user cl_owner nosuperuser nocreatedb login password 'cl_owner';
create schema cl_owner authorization cl_owner;
create user cl_user nosuperuser nocreatedb login password 'cl_user';
grant usage on schema cl_owner to cl_user;
alter default privileges in schema cl_owner grant select,insert,update,delete on tables to cl_user;
alter role cl_user set search_path to "$user",cl_owner,public;
\q
Let’s open the firewall port 5432
# as root
firewall-cmd --add-port 5432/tcp --permanent
systemctl restart firewalld
Before cloning the server (we need 3 servers) I will install the packages repmgr and pgpool. After that we can clone the server (it is a VM !), set-up the streaming replication with repmgr and then configure pgpool
1.2 repmgr
Repmgr is a nice open-source tool made by 2ndquadrant. It is not mandatory to use it and at first it maybe worth to set-up the streaming replication using standard postgres commands, for learning purpose. But otherwise it is really worth using repmgr because it brings very well tested and documented scripts. Note that repmgr can also be used to automate the failover (via the repmgrd daemon process) but we don’t want that because we will use pgpool.
MAJORVER=11
REPMGRVER=4.2
curl https://dl.2ndquadrant.com/default/release/get/${MAJORVER}/rpm | bash
yum install -y --enablerepo=2ndquadrant-dl-default-release-pg${MAJORVER} --disablerepo=pgdg${MAJORVER} repmgr${MAJORVER}-${REPMGRVER}
mkdir /var/log/repmgr && chown postgres:postgres /var/log/repmgr
set ownership of /etc/repmgr to postgres
chown -R postgres:postgres /etc/repmgr
1.3 install pgpool
This is just about installing the rpm, the configuration will be done later. The configuration has to be done on each server but we can already install pgpool before cloning the server. Adding pgpool on Centos is easy: install the pgpool release rpm (it will create a repo file in /etc/yum.repo.d) and then install pgpool itself via yum.
export PGPOOLMAJOR=4.0
export PGPOOLVER=4.0.3
export PGVER=11
yum install -y http://www.pgpool.net/yum/rpms/${PGPOOLMAJOR}/redhat/rhel-7-x86_64/pgpool-II-release-${PGPOOLMAJOR}-1.noarch.rpm
yum install --disablerepo=pgdg11 --enablerepo=pgpool40 -y pgpool-II-pg11-${PGPOOLVER} pgpool-II-pg11-extensions-${PGPOOLVER} pgpool-II-pg11-debuginfo-${PGPOOLVER}
``
I prefer to have pgpool running as user postgres, so I will override the systemd unit file that was installed by the rpm
```bash
# as user root
mkdir /etc/systemd/system/pgpool.service.d
cat <<EOF > /etc/systemd/system/pgpool.service.d/override.conf
[Service]
User=postgres
Group=postgres
EOF
Since pgpool connects to the various postgres servers via ssh, I add a few config to the ssh client to make ssh connections easier
cat <<EOF > /etc/ssh/ssh_config
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
EOF
Since I will use postgres user to start pgpool, I will change the ownership of /opt/pgpool-II
sudo chown postgres:postgres -R /etc/pgpool-II
I also need to create a directory for the pid file and the socket file
sudo mkdir /var/run/pgpool
sudo chown postgres:postgres /var/run/pgpool
1.4 Clone the servers
Now that I have pg01 ready, I will clone it to pg02 and pg03
I am using virsh (KVM) to manage my guests, those are the commands I used to clone my VM (the VM was created with this procedure http://saule1508.github.io/libvirt-centos-cloud-image)
Note: this is mostly for my own record, your way of cloning a VM might be different of course or you might have physical servers or you might use ansible to automate the provisioning,…
# on my host
virsh shutdown pg01
sudo mkdir /u01/virt/{pg02,pg03}
sudo chown pierre:pierre /u01/virt/pg02 /u01/virt/pg03
virt-clone -o pg01 -n pg02 --file /u01/virt/pg02/pg02.qcow2 --file /u01/virt/pg02/pg02-disk1.qcow2
virt-clone -o pg01 -n pg03 --file /u01/virt/pg03/pg03.qcow2 --file /u01/virt/pg03/pg03-disk1.qcow2
Now start the VM, get into it and change its IP address. To have a DNS, I also add an entry in /etc/hosts of the KVM host
# /etc/hosts of the KVM server, add one entry per vm so that they can speak to each other via dns
# added
192.168.122.10 pg01.localnet
192.168.122.11 pg02.localnet
192.168.122.13 pg03.localnet
when doing so, one must stop and start the default network then restart libvirtd
virsh net-destroy default
virsh net-start default
sudo systemctl restart libvirtd
Connect to each VM via ssh, change the IP address and the hostname (hostname-ctl set-hostname)
2. Set-up streaming replication with repmgr
Now I have 3 centos 7 VM with postgres, repmgr and pgpool installed. The 3 VM can resolve each other names via DNS but alternatively we could put 3 entries in the /etc/hosts file on each VM
| Host | IP |
|---|---|
| pg01.localnet | 192.168.122.10 |
| pg02.localnet | 192.168.122.11 |
| pg03.localnet | 192.168.122.12 |
We will use repmgr to set-up the 3 postgres instances in a primary - standby configuration where pg01 will be the primary. pg01 will be streaming his write ahead logs (wal) to pg02 and pg03.
First we want to set-up ssh keys so that each servers can connect to each other with the user postgres. On each server, generate a ssh keys pairt for user postgres and transfer the public key to both other servers.
# on pg01 as user postgres. Keep the default (no passphrase)
ss-keygen -t rsa
ssh-copy-id postgres@pg01.localnet
ssh-copy-id postgres@pg02.localnet
ssh-copy-id postgres@pg03.localnet
From pg01 postgres user must be able to connect to pg02 and pg03 but also to pg01 (itself) via ssh without a password. This is because pgpool - running on those servers - will connect via ssh to any of the postgres server to perform some operation (standby promote, standby follow, node recovery)
do the same on server pg02 and on server pg03
2.1 primary database on pg01
For the streaming replication we will be using the user repmgr with password rep123. Let’s create it.
create the user repmgr
# on pg01 as user postgres
psql <<-EOF
create user repmgr with superuser login password 'rep123' ;
alter user repmgr set search_path to repmgr,"\$user",public;
\q
EOF
create a database called repmgr
# on pg01 as user postgres
psql --command "create database repmgr with owner=repmgr ENCODING='UTF8' LC_COLLATE='en_US.UTF8';"
We want to connect with repmgr without password, that’s what the pgpass hidden file is for.
# on pg01 as user postgres
echo "*:*:repmgr:repmgr:rep123" > /home/postgres/.pgpass
echo "*:*:replication:repmgr:rep123" >> /home/postgres/.pgpass
chmod 600 /home/postgres/.pgpass
scp /home/postgres/.pgpass pg02.localnet:/home/postgres/.pgpass
scp /home/postgres/.pgpass pg03.localnet:/home/postgres/.pgpass
Add entries in $PGDATA/pg_hba.conf for repmgr
# on pg01 as user postgres
cat <<EOF >> $PGDATA/pg_hba.conf
# replication manager
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 0.0.0.0/0 md5
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 0.0.0.0/0 md5
host all all 0.0.0.0/0 md5
EOF
sudo systemctl restart postgresql
create the repmgr configuration file
# on pg01 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=1
node_name=pg01.localnet
conninfo='host=pg01.localnet dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
# event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n "%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f %p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl start postgresql'
service_stop_command = 'sudo systemctl stop postgresql'
service_restart_command = 'sudo systemctl restart postgresql'
service_reload_command = 'pg_ctl reload'
promote_command='repmgr -f /etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f /etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
Now register this database as being the primary database
# on pg01 as user postgres
repmgr -f /etc/repmgr/11/repmgr.conf -v master register
repmgr maintains information about the cluster topology in a table called nodes
psql -U repmgr repmgr -c "select * from nodes;"
We can now enable the systemd unit postgresql, so that postgres will be started on next boot
# on pg01
sudo systemctl enable postgresql
2.2. Standby database on pg02
Now we can go to the first standby, pg02, and set-it up as a standby
# on pg02 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=2
node_name=pg02.localnet
conninfo='host=pg02.localnet dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
# event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n "%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f %p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl start postgresql'
service_stop_command = 'sudo systemctl stop postgresql'
service_restart_command = 'sudo systemctl restart postgresql'
service_reload_command = 'pg_ctl reload'
promote_command='repmgr -f /etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f /etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
let’s wipe out the database and the archived wal
# make sure postgres is not running !
sudo systemctl stop postgresql
# on pg02 as user postgres
rm -rf /u01/pg11/data/*
rm -rf /u02/archive/*
And now let’s set-up this server as a standby
repmgr -h pg01.localnet -U repmgr -d repmgr -D /u01/pg11/data -f /etc/repmgr/11/repmgr.conf standby clone
sudo systemctl start postgresql
repmgr -f /etc/repmgr/11/repmgr.conf standby register --force
if it does not work, check that you can connect to pg01.localnet (maybe you forgot the firewall ?): psql -h pg01.localnet -U repmgr repmgr should work
we can enable the unit postgresql so that postgres will start automatically on next reboot
sudo systemctl enable postgresql
The nodes table should now have two records
psql -U repmgr -c "select * from nodes;"
2.3. Standby database on pg03
Let us do the same on the third standby, pg03, and set-it up as a standby
# on pg03 as user postgres
cat <<EOF > /etc/repmgr/11/repmgr.conf
node_id=3
node_name=pg03.localnet
conninfo='host=pg03.localnet dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
data_directory='/u01/pg11/data'
use_replication_slots=yes
# event_notification_command='/opt/postgres/scripts/repmgrd_event.sh %n "%e" %s "%t" "%d" %p %c %a'
reconnect_attempts=10
reconnect_interval=1
restore_command = 'cp /u02/archive/%f %p'
log_facility=STDERR
failover=manual
monitor_interval_secs=5
pg_bindir='/usr/pgsql-11/bin'
service_start_command = 'sudo systemctl start postgresql'
service_stop_command = 'sudo systemctl stop postgresql'
service_restart_command = 'sudo systemctl restart postgresql'
service_reload_command = 'pg_ctl reload'
promote_command='repmgr -f /etc/repmgr/11/repmgr.conf standby promote'
follow_command='repmgr -f /etc/repmgr/11/repmgr.conf standby follow -W --upstream-node-id=%n'
EOF
let’s wipe out the database and the archived wal
# make sure postgres is not running !
sudo systemctl stop postgresql
# on pg03 as user postgres
rm -rf /u01/pg11/data/*
rm -rf /u02/archive/*
And now let’s set-up this server as a standby
repmgr -h pg01.localnet -U repmgr -d repmgr -D /u01/pg11/data -f /etc/repmgr/11/repmgr.conf standby clone
sudo systemctl start postgresql
repmgr -f /etc/repmgr/11/repmgr.conf standby register --force
we can enable the unit postgresql so that postgres will start automatically on next reboot
sudo systemctl enable postgresql
Check the repmgr tables nodes
psql -U repmgr repmgr -c "select * from nodes;"
2.4. Test streaming replication
# on pg01 as user postgres
# check the nodes table, it contains meta-data for repmgr
psql -U repmgr repmgr -c "select * from nodes;"
# create a test table
psql -U repmgr repmgr -c "create table test(c1 int, message varchar(120)); insert into test values(1,'this is a test');"
# check on pg02 if I can see the table and if it is read-only
psql -h pg02.localnet -U repmgr repmgr <<EOF
select * from test;
drop table test;
EOF
# it will say: ERROR: cannot execute DROP TABLE in a read-only transaction
# check on pg03 if I can see the table and if it is read-only
psql -h pg03.localnet -U repmgr repmgr <<EOF
select * from test;
drop table test;
EOF
# drop the table on pg01
psql -U repmgr repmgr -c "drop table test;"
Experiment a bit with basis operations: failover, switch-over, following a new master, rejoining a failed primary, etc. repmgr has scripts for all of that.
3. pgpool
Now it is time to configure pgpool on our 3 servers. pgpool can be used as a connection cache but - more importantly - it is used to automate the failover of postgres and to make the failover (almost) transparent to client applications.
Remember that postgres is made HA (High Available) via the streaming replication and that pgpool is made HA via a Virtual IP (VIP) managed by the watchdog mode.
The following line muse be added to the postgres config (not sure why and if it is still needed)
echo "pgpool.pg_ctl='/usr/pgsql-11/bin/pg_ctl'" >> $PGDATA/conf.d/custom.conf
3.1. pgool_hba and pool_passwd files
similar to the postgres host based authentification mechanism (pg_hba), pgpool has a pool_hba.conf file.
cat <<EOF > /etc/pgpool-II/pool_hba.conf
local all all trust
# IPv4 local connections:
host all all 0.0.0.0/0 md5
EOF
scp /etc/pgpool-II/pool_hba.conf postgres@pg02.localnet:/etc/pgpool-II/
scp /etc/pgpool-II/pool_hba.conf postgres@pg03.localnet:/etc/pgpool-II/
Because I use md5, I will need to have the file pool_passwd containing the md5 hashed password http://www.pgpool.net/docs/latest/en/html/runtime-config-connection.html#GUC-POOL-PASSWD
# first dump the info into a temp file
psql -c "select rolname,rolpassword from pg_authid;" > /tmp/users.tmp
touch /etc/pgpool-II/pool_passwd
# then go through the file to remove/add the entry in pool_passwd file
cat /tmp/users.tmp | awk 'BEGIN {FS="|"}{print $1" "$2}' | grep md5 | while read f1 f2
do
echo "setting passwd of $f1 in /etc/pgpool-II/pool_passwd"
# delete the line if exits
sed -i -e "/^${f1}:/d" /etc/pgpool-II/pool_passwd
echo $f1:$f2 >> /etc/pgpool-II/pool_passwd
done
scp /etc/pgpool-II/pool_passwd pg02:/etc/pgpool-II/pool_passwd
scp /etc/pgpool-II/pool_passwd pg03:/etc/pgpool-II/pool_passwd
⚠️ Everytime a new postgres user is added or her password is changed this small procedure must be re-ran
3.2. Setting up pcp.conf file
pcp (pgpool control protocol) is an administrative interface to pgpool, it enables you to interact with pgpool via port 9898 (default). The file pcp.conf stores a username and a md5 password to authentificate, the file .pcppass enables a user to use pcp commands without password. Note that this user/password is not related to a postgres user, it is just a pcp user that can speak with pgpool via the pcp protocol. http://www.pgpool.net/docs/latest/en/html/configuring-pcp-conf.html
I will use the user postgres with password secret
# user postgres on pg01
echo "postgres:$(pg_md5 secret)" >> /etc/pgpool-II/pcp.conf
scp /etc/pgpool-II/pcp.conf pg02:/etc/pgpool-II/pcp.conf
scp /etc/pgpool-II/pcp.conf pg03:/etc/pgpool-II/pcp.conf
echo "*:*:postgres:secret" > /home/postgres/.pcppass
chown postgres:postgres /home/postgres/.pcppass
chmod 600 /home/postgres/.pcppass
scp /home/postgres/.pcppass pg02:/home/postgres/.pcppass
scp /home/postgres/.pcppass pg03:/home/postgres/.pcppass
because of this .pcppass we will be able to use pcp without password when logged in as unix user postgres.
In watchdog mode, pgpool will need to execute the ip and the arping commands with user postgres, so we set the sticky bit on those two utilities.
chmod 4755 /usr/sbin/ip /usr/sbin/arping
3.3. Pgpool configuration file: pgpool.conf
The 3 servers used in the config are pg01.localnet, pg02.localnet and pg03.localnet. We also need a VIP (virtual IP, also called delegate_ip in the context of pgpool). In my case the VIP will be 192.168.122.50.
This is the config I use for the first server, I will explain it below. Take care that because I do a cat redirected to the config, I have to escape the dollar signs in the config. Pay attention to if_up_cmd below for example, I escaped the $ but in the file it must of course not be escaped.
# as user postgres on pg01
CONFIG_FILE=/etc/pgpool-II/pgpool.conf
cat <<EOF > $CONFIG_FILE
listen_addresses = '*'
port = 9999
socket_dir = '/var/run/pgpool'
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/var/run/pgpool'
listen_backlog_multiplier = 2
serialize_accept = off
enable_pool_hba = on
pool_passwd = 'pool_passwd'
authentication_timeout = 60
ssl = off
num_init_children = 100
max_pool = 5
# - Life time -
child_life_time = 300
child_max_connections = 0
connection_life_time = 600
client_idle_limit = 0
log_destination='stderr'
debug_level = 0
pid_file_name = '/var/run/pgpool/pgpool.pid'
logdir = '/tmp'
connection_cache = on
reset_query_list = 'ABORT; DISCARD ALL'
#reset_query_list = 'ABORT; RESET ALL; SET SESSION AUTHORIZATION DEFAULT'
replication_mode = off
load_balance_mode = off
master_slave_mode = on
master_slave_sub_mode = 'stream'
backend_hostname0 = 'pg01.localnet'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/u01/pg11/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'pg02.localnet'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/u01/pg11/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_hostname2 = 'pg03.localnet'
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 = '/u01/pg11/data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
# this is about checking the postgres streaming replication
sr_check_period = 10
sr_check_user = 'repmgr'
sr_check_password = 'rep123'
sr_check_database = 'repmgr'
delay_threshold = 10000000
# this is about automatic failover
failover_command = '/opt/pgpool/scripts/failover.sh %d %h %P %m %H %R'
# not used, just echo something
failback_command = 'echo failback %d %h %p %D %m %H %M %P'
failover_on_backend_error = 'off'
search_primary_node_timeout = 300
# Mandatory in a 3 nodes set-up
follow_master_command = '/opt/pgpool/scripts/follow_master.sh %d %h %m %p %H %M %P'
# grace period before triggering a failover
health_check_period = 40
health_check_timeout = 10
health_check_user = 'hcuser'
health_check_password = 'hcuser'
health_check_database = 'postgres'
health_check_max_retries = 3
health_check_retry_delay = 1
connect_timeout = 10000
#------------------------------------------------------------------------------
# ONLINE RECOVERY
#------------------------------------------------------------------------------
recovery_user = 'repmgr'
recovery_password = 'rep123'
recovery_1st_stage_command = 'pgpool_recovery.sh'
recovery_2nd_stage_command = 'echo recovery_2nd_stage_command'
recovery_timeout = 90
client_idle_limit_in_recovery = 0
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
use_watchdog = on
# trusted_servers = 'www.google.com,pg02.localnet,pg03.localnet' (not needed with a 3 nodes cluster ?)
ping_path = '/bin'
wd_hostname = pg01.localnet
wd_port = 9000
wd_priority = 1
wd_authkey = ''
wd_ipc_socket_dir = '/var/run/pgpool'
delegate_IP = '192.168.122.99'
if_cmd_path = '/opt/pgpool/scripts'
if_up_cmd = 'ip_w.sh addr add \$_IP_\$/24 dev eth0 label eth0:0'
if_down_cmd = 'ip_w.sh addr del \$_IP_\$/24 dev eth0'
arping_path = '/opt/pgpool/scripts'
arping_cmd = 'arping_w.sh -U \$_IP_\$ -I eth0 -w 1'
# - Behaivor on escalation Setting -
heartbeat_destination0 = 'pg01.localnet'
heartbeat_destination_port0 = 9694
heartbeat_destination1 = 'pg02.localnet'
heartbeat_destination_port1 = 9694
heartbeat_destination2 = 'pg03.localnet'
heartbeat_destination_port2 = 9694
other_pgpool_hostname0 = 'pg02.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = 'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
EOF
Let’s copy the file to pg02.localnet and pg03.localnet and make the necessary adaptations in the sections
scp /etc/pgpool-II/pgpool.conf pg02.localnet:/etc/pgpool-II/pgpool.conf
on pg02.localnet, changes
wd_hostname = pg02.localnet
other_pgpool_hostname0 = 'pg01.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = 'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
And the same to pg03.localnet
⚠️ when there is an issue with the watchdog of pgpool the reason is very often that the config is not correct, for example one forgot to adapt the other_pgpool_hostname section on each node.
3.4. Some pgpool parameters explained:
- params related to streaming replication.
I prefer to set load_balance to ‘off’ but it might be a useful feature in some cases. By setting master_slave_mode on and sub mode to stream we are telling pgpool that we use standard postgres streaming replication mechanism.
load_balance_mode = off
master_slave_mode = on
master_slave_sub_mode = 'stream'
The backend section describes the 3 postgres
backend_hostname0 = 'pg01.localnet'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/u01/pg11/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
etc... for pg02 and pg03
- num_init_children and max_pool relate to the connection caching functionality of pgpool.
When pgpool starts it will create “num_init_children” client processes that will all be in a state “waiting for a connection”. When a client application connects to pgpool, pgpool will use one of the child process that is free and establish a connection to postgres. When the client disconnects then pgpool will keep the connection to postgres open (connection caching) so that next time a client connect to pgpool the connection to postgres can be re-used and we avoid the cost of creating a new connection. We can disable this connection caching if we prefer to have pooling at the application level.
- parameters related to automatic failover
failover_command is the script that will be executed when pgpool detects (via health check mechanism in my case) that the primary database is down. I don’t know what the failback_command is supposed to do, I just don’t use it. The follow_master_command is executed on all standby nodes after the failover_command was executed and a new primary database has been detected. I wil show the corresponding scripts later in this document.
failover_command = '/opt/pgpool/scripts/failover.sh %d %h %P %m %H %R'
failback_command = 'echo failback %d %h %p %D %m %H %M %P'
search_primary_node_timeout = 300
follow_master_command = '/opt/pgpool/scripts/follow_master.sh %d %h %m %p %H %M %P'
The first reason why people need pgpool is because pgpool can automate the failover and make it transparent to client applications. There are basically two mechanisms to trigger a failover. Either via failover_on_backend_error or via the health checks. I prefer to set failover_on_backend_error to off and to use the health check mechanism to trigger the failover. The health check mechanism means that pgpool will regularly connect to postgres, if a connection fails (either to a primary or to a standby) then after the number of retries it will trigger the failover.
failover_on_backend_error = 'off'
health_check_period = 40
health_check_timeout = 10
health_check_user = 'hcuser'
health_check_password = 'hcuser'
health_check_database = 'postgres'
health_check_max_retries = 3
health_check_retry_delay = 1
If you set failover_on_backend_error to ‘on’, then pgpool will trigger the failover when one of the child process detects that postgres is terminated. In this case there is no retry. Note also that in this case, as long as no application connect to pgpool or perform a query on the database, no failover will be triggered.
Do not confuse the health check with the streaming replication check (the streaming replication check look at the delay in replication, if the delay is too big a standby will ne be used for read load balancing and will not be considered for promotion). For some strange reason pgpool uses two different users for these.
- parameters related to watch-dog
The watch-dog mechanism is a very cool functionality of pgpool: multiple instances of pgpool (3 in our case) are in an active-passive set-up, on startup the cluster elects one leader and the leader acquires the VIP (delegate_ip). The 3 nodes are monitoring each other and if the primary fails then a new leader will be elected and the VIP will be moved to this new leader.
Only the leader pgpool node will execute the failover, follow_master, etc. commands
The watchdog mode must be enabled via use_watchdog (‘on’)
The nodes monitor each other via the heartbeat mechanism, sending a packet on UDP port 9694 to the other nodes
heartbeat_destination0 = 'pg01.localnet'
heartbeat_destination_port0 = 9694
heartbeat_destination1 = 'pg02.localnet'
heartbeat_destination_port1 = 9694
heartbeat_destination2 = 'pg03.localnet'
heartbeat_destination_port2 = 9694
The VIP is acquired via a script that must be installed on the host.
if_cmd_path = '/opt/pgpool/scripts'
if_up_cmd = 'ip_w.sh addr add $_IP_$/24 dev eth0 label eth0:0'
if_down_cmd = 'ip_w.sh addr del $_IP_$/24 dev eth0'
arping_path = '/opt/pgpool/scripts'
arping_cmd = 'arping_w.sh -U $_IP_$ -I eth0 -w 1'
In the command above, pgpool will replace $IP$ with the value of the delegate_ip parameter
delegate_ip = 192.168.122.99
each node must be aware of the others, so on pg01
wd_hostname = pg01
wd_port = 9000
wd_priority = 1
wd_authkey = ''
wd_ipc_socket_dir = '/var/run/pgpool'
other_pgpool_hostname0 = 'pg02.localnet'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = 'pg03.localnet'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
- log destination
I use the default log_destination = ‘stderr’ and I look at the logs via journalctl
sudo journalctl --unit pgpool
3.5. pgpool preparation
we need to create the postgres user for the health check
# on pg01 as user postgres
psql -c "create user hcuser with login password 'hcuser';"
We need to open a few firewall ports, for pgpool (9999 and 9898 for pcp) and for the watch-dog functionality
# on all 3 servers
# port for postgres (was already done)
sudo firewall-cmd --add-port 9898/tcp --permanent
# ports for pgpool and for pcp
sudo firewall-cmd --add-port 9898/tcp --permanent
sudo firewall-cmd --add-port 9999/tcp --permanent
sudo firewall-cmd --add-port 9000/tcp --permanent
sudo firewall-cmd --add-port 9694/udp --permanent
sudo systemctl restart firewalld
Directory for pid file
# on all servers
sudo chown postgres:postgres /var/run/pgpool
sudo mkdir /var/log/pgpool
sudo chown postgres:postgres /var/log/pgpool
pgpool scripts will logs into /var/log/pgpool.
If you want also logs of pgpool itself, then use as log_destination = ‘stderr,syslog’ and set syslog_facility to LOCAL1, and configure syslog. Add to /etc/rsyslog.conf
local1.* /var/log/pgpool/pgpool.log
then restart the daemon
sudo systemctl restart rsyslog
nb: not sure this is working though, not tested.
3.5. Pgpool Scripts
sudo mkdir -p /opt/pgpool/scripts
sudo chown postgres:postgres /opt/pgpool/scripts
- failover script
Copy and paste the following in /opt/pgpoo/scripts/failover.sh
#!/bin/bash
LOGFILE=/var/log/pgpool/failover.log
if [ ! -f $LOGFILE ] ; then
> $LOGFILE
fi
# we need this, otherwise it is not set
PGVER=${PGVER:-11}
#
#failover_command = '/scripts/failover.sh %d %h %P %m %H %R'
# Executes this command at failover
# Special values:
# %d = node id
# %h = host name
# %p = port number
# %D = database cluster path
# %m = new master node id
# %H = hostname of the new master node
# %M = old master node id
# %P = old primary node id
#
FALLING_NODE=$1 # %d
FALLING_HOST=$2 # %h
OLD_PRIMARY_ID=$3 # %P
NEW_PRIMARY_ID=$4 # %m
NEW_PRIMARY_HOST=$5 # %H
NEW_MASTER_PGDATA=$6 # %R
(
date
echo "FALLING_NODE: $FALLING_NODE"
echo "FALLING_HOST: $FALLING_HOST"
echo "OLD_PRIMARY_ID: $OLD_PRIMARY_ID"
echo "NEW_PRIMARY_ID: $NEW_PRIMARY_ID"
echo "NEW_PRIMARY_HOST: $NEW_PRIMARY_HOST"
echo "NEW_MASTER_PGDATA: $NEW_MASTER_PGDATA"
ssh_options="ssh -p 22 -n -T -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
set -x
if [ $FALLING_NODE = $OLD_PRIMARY_ID ] ; then
$ssh_options postgres@${NEW_PRIMARY_HOST} "/usr/pgsql-${PGVER}/bin/repmgr --log-to-file -f /etc/repmgr/${PGVER}/repmgr.conf standby promote -v "
fi
exit 0;
make it executable
- follow_master
Copy the following in /opt/pgpool/scripts/follow_master.sh
#!/bin/bash
LOGFILE=/var/log/pgpool/follow_master.log
if [ ! -f $LOGFILE ] ; then
> $LOGFILE
fi
PGVER=${PGVER:-11}
echo "executing follow_master.sh at `date`" | tee -a $LOGFILE
NODEID=$1
HOSTNAME=$2
NEW_MASTER_ID=$3
PORT_NUMBER=$4
NEW_MASTER_HOST=$5
OLD_MASTER_ID=$6
OLD_PRIMARY_ID=$7
PGDATA=${PGDATA:-/u01/pg${PGVER}/data}
(
echo NODEID=${NODEID}
echo HOSTNAME=${HOSTNAME}
echo NEW_MASTER_ID=${NEW_MASTER_ID}
echo PORT_NUMBER=${PORT_NUMBER}
echo NEW_MASTER_HOST=${NEW_MASTER_HOST}
echo OLD_MASTER_ID=${OLD_MASTER_ID}
echo OLD_PRIMARY_ID=${OLD_PRIMARY_ID}
echo PGDATA=${PGDATA}
if [ $NODEID -eq $OLD_PRIMARY_ID ] ; then
echo "Do nothing as this is the failed master. We could prevent failed master to restart here, so that we can investigate the issue" | tee -a $LOGFILE
else
ssh_options="ssh -p 22 -n -T -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
set -x
# if this node is not currently standby then it might be an old master that went back up after a failover occured
# if this is the case we cannot do the follow master command on this node, we should leave it alone
in_reco=$( $ssh_options postgres@${HOSTNAME} 'psql -t -c "select pg_is_in_recovery();"' | head -1 | awk '{print $1}' )
echo "pg_is_in_recovery on $HOSTNAME is $in_reco " | tee -a $LOGFILE
if [ "a${in_reco}" != "at" ] ; then
echo "node $HOSTNAME is not in recovery, probably a degenerated master, skip it" | tee -a $LOGFILE
exit 0
fi
$ssh_options postgres@${HOSTNAME} "/usr/pgsql-${PGVER}/bin/repmgr --log-to-file -f /etc/repmgr/${PGVER}/repmgr.conf -h ${NEW_MASTER_HOST} -D ${PGDATA} -U repmgr -d repmgr standby follow -v "
# TODO: we should check if the standby follow worked or not, if not we should then do a standby clone command
echo "Sleep 10"
sleep 10
echo "Attach node ${NODEID}"
pcp_attach_node -h localhost -p 9898 -w ${NODEID}
fi
) 2>&1 | tee -a $LOGFILE
- pgpool_recovery script
the script pgpool_recovery.sh must be installed in $PGDATA, must be owned by postgres and have execute permission. This script will be called via the postgres extension pgpool_recovery, so we must first install this extension.
# on the primary db only
psql -c "create extension pgpool_recovery;" -d template1
psql -c "create extension pgpool_adm;"
pgpool_adm is another extension that you may want to install
create the file $PGDATA/pgpool_recovery.sh (in my case $PGDATA is /u01/pg11/data). I also install this script in /opt/pgpool/scripts. to keep a copy.
#!/bin/bash
# This script erase an existing replica and re-base it based on
# the current primary node. Parameters are position-based and include:
#
# 1 - Path to primary database directory.
# 2 - Host name of new node.
# 3 - Path to replica database directory
#
# Be sure to set up public SSH keys and authorized_keys files.
# this script must be in PGDATA
PGVER=${PGVER:-11}
ARCHIVE_DIR=/u02/archive
LOGFILE=/var/log/pgool/pgpool_recovery.log
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
log_info(){
echo $( date +"%Y-%m-%d %H:%M:%S.%6N" ) - INFO - $1 | tee -a $LOGFILE
}
log_error(){
echo $( date +"%Y-%m-%d %H:%M:%S.%6N" ) - ERROR - $1 | tee -a $LOGFILE
}
log_info "executing pgpool_recovery at `date` on `hostname`"
PATH=$PATH:/usr/pgsql-${PGVER}/bin
if [ $# -lt 3 ]; then
echo "Create a replica PostgreSQL from the primary within pgpool."
echo
echo "Usage: $0 PRIMARY_PATH HOST_NAME COPY_PATH"
echo
exit 1
fi
# to do is hostname -i always OK ? Find other way to extract the host. maybe from repmgr.conf ?
primary_host=$(hostname -i) # not working on SCM
replica_host=$2
replica_path=$3
log_info "primary_host: ${primary_host}"
log_info "replica_host: ${replica_host}"
log_info "replica_path: ${replica_path}"
ssh_copy="ssh -p 22 postgres@$replica_host -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
log_info "Stopping postgres on ${replica_host}"
$ssh_copy "sudo systemctl stop postgresql"
log_info sleeping 10
sleep 10
log_info "delete database directory on ${replica_host}"
$ssh_copy "rm -Rf $replica_path/* $ARCHIVE_DIR/*"
log_info "let us use repmgr on the replica host to force it to sync again"
$ssh_copy "/usr/pgsql-${PGVER}/bin/repmgr -h ${primary_host} --username=repmgr -d repmgr -D ${replica_path} -f /etc/repmgr/${PGVER}/repmgr.conf standby clone -v"
log_info "Start database on ${replica_host} "
$ssh_copy "sudo systemctl start postgresql"
log_info sleeping 20
sleep 20
log_info "Register standby database"
$ssh_copy "/usr/pgsql-${PGVER}/bin/repmgr -f /etc/repmgr/${PGVER}/repmgr.conf standby register -F -v"
Do not forget to install it in $PGDATA and to set execute permission
chmod 774 /opt/pgpool/scripts/pgpool_recovery.sh
cp /opt/pgpool/scripts/pgpool_recovery.sh $PGDATA/pgpool_recovery.sh
scp /opt/pgpool/scripts/pgpool_recovery.sh pg02.localnet:$PGDATA/
scp /opt/pgpool/scripts/pgpool_recovery.sh pg03.localnet:$PGDATA/
for the watchdog mode, we need two additional scripts
- ip scripts
Create the file /opt/pgool/scripts/ip_w.sh
#!/bin/bash
echo "Exec ip with params $@ at `date`"
sudo /usr/sbin/ip $@
exit $?
Create the file /opt/pgpool/scripts/arping_w.sh
#!/bin/bash
echo "Exec arping with params $@ at `date`"
sudo /usr/sbin/arping $@
exit $?
Now set execute mode on all scripts and copy them over to pg02 and pg03
chmod 774 /opt/pgpool/scripts/*
scp /opt/pgpool/scripts/* pg02.localnet:/opt/pgpool/scripts/
scp /opt/pgpool/scripts/* pg03.localnet:/opt/pgpool/scripts/
4. Test the set-up
Before starting pgpool on nodes pg01.localnet, pg02.localnet and pg03.localnet let’s do final checks
- check streaming replication
# on pg01
repmgr -f /etc/repmgr/11/repmgr.conf cluster show
- enable postgressql and pgpool services on all servers
sudo systemctl enable postgresql
sudo systemctl enable pgpool
- check firewall on all servers
sudo firewall-cmd --list-all
- check ssh connectivity between all servers
remember that pg01 will connect to itself via ssh also, and pg02/3 also
start pgpool on pg01.localnet, pg02.localnet and pg03.localnet
sudo systemctl start pgpool
as soon as there is a quorum (two nodes), pgpool will elect a leader and it will acquire the VIP
Since pgpool is logging to stderr, we can see the logs with journalctl
sudo journalctl --unit pgpool -f
Have a good look at the logs, it is a bit verbose but very relevant. Once you start pgpool on pg02.localnet and pg03.localnet, you should see in the log that a master was elected and that the VIP was acquired. The VIP will be on the master node, in my case pg01.localnet (it started first)
get info about the pgpool cluster
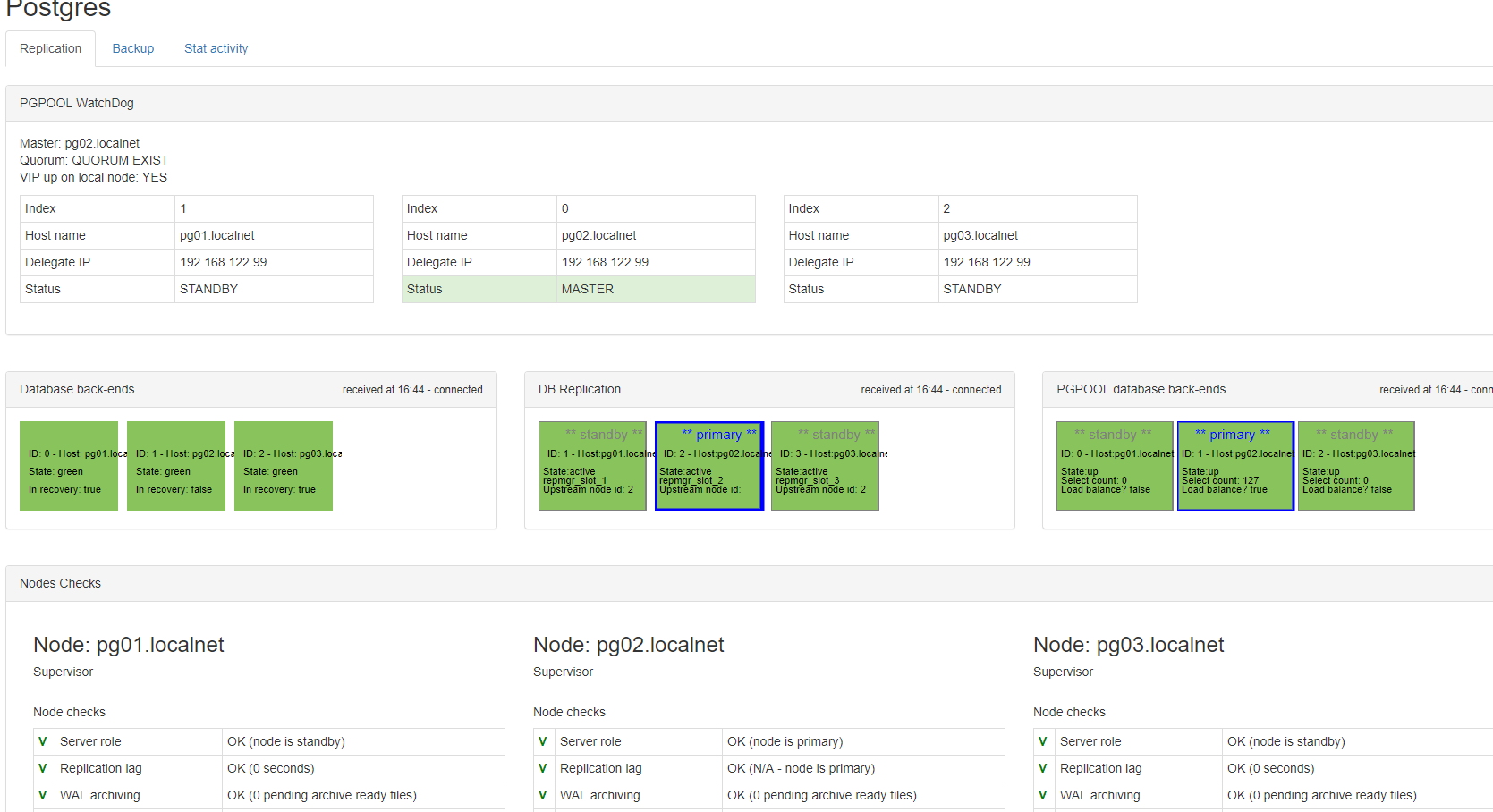
pcp_watchdog_info -h 192.168.122.99 -p 9898 -w -v
the -w flag is to avoid password prompt, it requires to have the pcp password for postgres in /home/postgres/.pcppass (the password md5 is defined in /etc/pgpool-II/pcp.conf)
# result of ip addr
[postgres@pg01 pgpool-II]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:b5:58:ec brd ff:ff:ff:ff:ff:ff
inet 192.168.122.10/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.122.99/24 scope global secondary eth0:0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feb5:58ec/64 scope link
valid_lft forever preferred_lft forever
the important info is that IP 192.168.122.99 was set-up on eth0 with label eth0:0
4.1. failover pgpool
before testing the failover, make sure that all nodes can connect to each other via ssh without a password prompt
# on pg01, pg02 and pg03
ssh -p 22 postgres@pg01.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f /etc/repmgr/${PGVER}/repmgr.conf --help"
ssh -p 22 postgres@pg02.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f /etc/repmgr/${PGVER}/repmgr.conf --help"
ssh -p 22 postgres@pg03.localnet -T -n -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no "repmgr -f /etc/repmgr/${PGVER}/repmgr.conf --help"
to test a failover of pgpool we need to stop pgpool on the master and see if a new master is elected and if the VIP is moved to the new master. Follow the logs during this operation because it gives all relevant information.
sudo systemctl stop pgpool
Check that the VIP was moved.
restart pgpool
sudo systemctl start pgpool
4.2. failover postgres
Let’s see the state of pgpool
psql -h 192.168.122.99 -p 9999 -U repmgr -c "show pool_nodes;"
let’s see also the replication stats on the primary and on the standby’s
# pg01 is the primary
psql -h pg01.localnet -p 5432 -U repmgr -c "select * from pg_stat_replication;"
psql -h pg02.localnet -p 5432 -U repmgr -c "select * from pg_stat_wal_receiver;"
psql -h pg03.localnet -p 5432 -U repmgr -c "select * from pg_stat_wal_receiver;"
since pg01.localnet is the primary, I will stop it and pgpool should promote pg02 to primary (failover script) and pg03 should now follow the new primary.
# on pg01
sudo systemctl stop postgresql
Check again pgpool status
psql -h 192.168.122.99 -p 9999 -U repmgr -c "show pool_nodes;"
check the log files failover.log and follow_master.log in /var/log/pgool on the pgpool master node
check with select * from pg_stat_wal_receiver; that the second stand-by follows the new primary and check with select * from pg_stat_replication; that the primary streams to the standby
4.3. recover failed node
There are different ways to rebase the failed primary as a standby
- using repmgr
assuming the new primary is pg02.localnet, executing the following so that pg01.localnet rejoin the cluster as a standby. Note that it will not always work
repmgr node rejoin -d 'host=pg02.localnet dbname=repmgr user=repmgr password=rep123 connect_timeout=2'
and then re-attach the node to pgpool
pcp_attach_node -h 192.168.122.99 -p 9898 -w 0
But the safest way is to rebuild it, using pcp_recovery_node. pgpool will use the parameters recovery_user and recovery_password to connect to the database and execute “select pg_recovery(…)”. The function pgpool_recovery was created when we installed the pgpool extension.
In our case we had
recovery_user = 'repmgr'
recovery_password = 'rep123'
pcp_recovery_node -h 192.168.122.99 -p 9898 -w 0
and then re-attach the node
pcp_attach_node -h 192.168.122.99 -p 9898 -w 0
4.4. Automatic recovery of a failed master or standby
In my company they wanted that a failed master (or a failed standby) that comes back to life would be automatically put back in the cluster as a standby. For example assuming this scenario:
- pg01 is the primary
- the server pg01 is powered off
- pg02 becomes the primary, pg03 follows pg02
- the server pg01 is powered on
- postgres on pg01 comes back, it is in read-write mode, however because it is detached from pgpool we are protected from a split-brain
we want that pg01 is automatically recoverd and becomes a standby of pg02 and rejoin the pgpool cluster
Another scenario is when a standby server is rebooted: pgpool will detach the standby database but when the server comes back pgpool will not re-attach it.
My solution was to schedule a script via cron. The script is the following. Take care that it must be adapted on pg02 and on pg03, the variable PG_NODE_ID is 0 on pg01, 1 on pg02 and 2 on pg03. Adapt also the var DELEGATE_IP (192.168.122.99 for me)
# content of /opt/postgres/scripts/recover_failed_node.sh (can be scheduled via cron)
#!/bin/bash
# this script will re-attach a failed standby database
# or recover a failed primary database
# it requires that pgpool is available and that the database on this node is running
# this script might be called when the postgres container is starting but then it must do so
# when both pgpool and the database is running. Since the db is started with supervisor, this would
# require to lauch the script in the background after the start of postgres
# the script can also be started manually or via cron
# Created by argbash-init v2.6.1
# ARG_OPTIONAL_BOOLEAN([auto-recover-standby],[],[reattach a standby to pgpool if possible],[on])
# ARG_OPTIONAL_BOOLEAN([auto-recover-primary],[],[recover the degenerated master],[off])
# ARG_OPTIONAL_SINGLE([lock-timeout-minutes],[],[minutes after which a lock will be ignored (optional)],[120])
# ARG_HELP([<The general help message of my script>])
# ARGBASH_GO()
# needed because of Argbash --> m4_ignore([
### START OF CODE GENERATED BY Argbash v2.6.1 one line above ###
# Argbash is a bash code generator used to get arguments parsing right.
# Argbash is FREE SOFTWARE, see https://argbash.io for more info
die()
{
local _ret=$2
test -n "$_ret" || _ret=1
test "$_PRINT_HELP" = yes && print_help >&2
echo "$1" >&2
exit ${_ret}
}
begins_with_short_option()
{
local first_option all_short_options
all_short_options='h'
first_option="${1:0:1}"
test "$all_short_options" = "${all_short_options/$first_option/}" && return 1 || return 0
}
# THE DEFAULTS INITIALIZATION - OPTIONALS
_arg_auto_recover_standby="on"
_arg_auto_recover_primary="off"
_arg_lock_timeout_minutes="120"
print_help ()
{
printf '%s\n' "<The general help message of my script>"
printf 'Usage: %s [--(no-)auto-recover-standby] [--(no-)auto-recover-primary] [--lock-timeout-minutes <arg>] [-h|--help]\n' "$0"
printf '\t%s\n' "--auto-recover-standby,--no-auto-recover-standby: reattach a standby to pgpool if possible (on by default)"
printf '\t%s\n' "--auto-recover-primary,--no-auto-recover-primary: recover the degenerated master (off by default)"
printf '\t%s\n' "--lock-timeout-minutes: minutes after which a lock will be ignored (optional) (default: '120')"
printf '\t%s\n' "-h,--help: Prints help"
}
parse_commandline ()
{
while test $# -gt 0
do
_key="$1"
case "$_key" in
--no-auto-recover-standby|--auto-recover-standby)
_arg_auto_recover_standby="on"
test "${1:0:5}" = "--no-" && _arg_auto_recover_standby="off"
;;
--no-auto-recover-primary|--auto-recover-primary)
_arg_auto_recover_primary="on"
test "${1:0:5}" = "--no-" && _arg_auto_recover_primary="off"
;;
--lock-timeout-minutes)
test $# -lt 2 && die "Missing value for the optional argument '$_key'." 1
_arg_lock_timeout_minutes="$2"
shift
;;
--lock-timeout-minutes=*)
_arg_lock_timeout_minutes="${_key##--lock-timeout-minutes=}"
;;
-h|--help)
print_help
exit 0
;;
-h*)
print_help
exit 0
;;
*)
_PRINT_HELP=yes die "FATAL ERROR: Got an unexpected argument '$1'" 1
;;
esac
shift
done
}
parse_commandline "$@"
# OTHER STUFF GENERATED BY Argbash
### END OF CODE GENERATED BY Argbash (sortof) ### ])
# [ <-- needed because of Argbash
printf "'%s' is %s\\n" 'auto-recover-standby' "$_arg_auto_recover_standby"
printf "'%s' is %s\\n" 'auto-recover-primary' "$_arg_auto_recover_primary"
printf "'%s' is %s\\n" 'lock-timeout-minutes' "$_arg_lock_timeout_minutes"
PIDFILE=/home/postgres/recover_failed_node.pid
trap cleanup EXIT
DELEGATE_IP=192.168.122.99
### adapt on each node ###
PGP_NODE_ID=0
PGP_STATUS_WAITING=1
PGP_STATUS_UP=2
PGP_STATUS_DOWN=3
LOGFILENAME="${PROGNAME%.*}.log"
LOGFILE=/var/log/postgres/${LOGFILENAME}
if [ ! -f $LOGFILE ] ; then
touch $LOGFILE
fi
log_info(){
echo $( date +"%Y-%m-%d %H:%M:%S.%6N" ) - INFO - $1 | tee -a $LOGFILE
}
log_error(){
echo $( date +"%Y-%m-%d %H:%M:%S.%6N" ) - ERROR - $1 | tee -a $LOGFILE
}
cleanup(){
# remove pid file but only if it is mine, dont remove if another process was running
if [ -f $PIDFILE ] ; then
MYPID=$$
STOREDPID=$(cat $PIDFILE)
if [ "${MYPID}" == "${STOREDPID}" ] ; then
rm -f $PIDFILE
fi
fi
if [ -z $INSERTED_ID ] ; then
return
fi
log_info "delete from recover_failed with id $INSERTED_ID"
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -t -c "delete from recover_failed_lock where id=${INSERTED_ID};"
}
# test if there is lock in the recover_failed_lock table
# return 0 if there is no lock, 1 if there is one
is_recovery_locked(){
# create table if not exists
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "create table if not exists recover_failed_lock(id serial,ts timestamp with time zone default current_timestamp,node varchar(10) not null,message varchar(120));"
#clean-up old records
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "delete from recover_failed_lock where ts < current_timestamp - INTERVAL '1 day';"
# check if there is already an operation in progress
str=$(psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "select ts,node from recover_failed_lock where ts > current_timestamp - INTERVAL '${_arg_lock_timeout_minutes} min';")
if [ $? -ne 0 ] ; then
log_error "psql error when selecting from recover_failed_lock table"
exit 1
fi
echo $str | grep "(0 rows)"
if [ $? -eq 0 ] ; then
return 0
fi
log_info "there is a lock record in recover_failed_lock : $str"
return 1
}
# take a lock on the the recovery operation
# by inserting a record in table recover_failed_lock
# fails if there is already a recovery running (if an old record still exist)
# exit -1 : error
# return 0: cannot acquire a lock because an operation is already in progress
lock_recovery(){
MSG=$1
# create table if not exists
psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -c "create table if not exists recover_failed_lock(id serial,ts timestamp with time zone default current_timestamp,node varchar(10) not null,message varchar(120));"
if [ $? -ne 0 ] ; then
log_error "Cannot create table recover_failed_lock table"
exit 1
fi
is_recovery_locked
if [ $? -eq 1 ] ; then
return 0
fi
str=$(psql -U repmgr -h $DELEGATE_IP -p 9999 repmgr -t -c "insert into recover_failed_lock (node,message) values ('${NODE_NAME}','${MSG}') returning id;")
if [ $? -ne 0 ] ; then
log_info "cannot insert into recover_failed_lock"
exit 1
fi
INSERTED_ID=$(echo $str | awk '{print $1}')
log_info "inserted lock in recover_failed_log with id $INSERTED_ID"
return $INSERTED_ID
}
pg_is_in_recovery(){
psql -t -c "select pg_is_in_recovery();" | head -1 | awk '{print $1}'
}
check_is_streaming_from(){
PRIMARY=$1
# first check if is_pg_in_recovery is t
in_reco=$( pg_is_in_recovery )
if [ "a${in_reco}" != "at" ] ; then
return 0
fi
psql -t -c "select * from pg_stat_wal_receiver;" > /tmp/stat_wal_receiver.tmp
# check that status is streamin
status=$( cat /tmp/stat_wal_receiver.tmp | head -1 | cut -f2 -d"|" | sed -e "s/ //g" )
if [ "a${status}" != "astreaming" ] ; then
log_info "status is not streaming"
return 0
fi
#check that is recovering from primary
conninfo=$( cat /tmp/stat_wal_receiver.tmp | head -1 | cut -f14 -d"|" )
echo $conninfo | grep "host=${PRIMARY}"
if [ $? -eq 1 ] ; then
log_info "not streaming from $PRIMARY"
return 0
fi
return 1
}
# arg: 1 message
recover_failed_master(){
# try to acquire a lock
MSG=$1
lock_recovery "$MSG"
LOCK_ID=$?
if [ ${LOCK_ID} -eq 0 ] ; then
log_info "cannot acquire a lock, probably an old operation is in progress ?"
return 99
fi
log_info "acquired lock $LOCK_ID"
#echo "First try node rejoin"
#echo "todo"
log_info "Do pcp_recovery_node of $PGP_NODE_ID"
pcp_recovery_node -h $DELEGATE_IP -p 9898 -w $PGP_NODE_ID
ret=$?
cleanup
return $ret
}
recover_standby(){
#dont do it if there is a lock on recover_failed_lock
is_recovery_locked
if [ $? -eq 1 ] ; then
return 0
fi
if [ "$_arg_auto_recover_standby" == "on" ] ; then
log_info "attach node back since it is in recovery streaming from $PRIMARY_NODE_ID"
pcp_attach_node -h $DELEGATE_IP -p 9898 -w ${PGP_NODE_ID}
if [ $? -eq 0 ] ; then
log_info "OK attached node $node back since it is in recovery and streaming from $PRIMARY_NODE_ID"
exit 0
fi
log_error "attach node failed for node $node"
exit 1
else
log_info "auto_recover_standby is off, do nothing"
exit 0
fi
}
if [ -f $PIDFILE ] ; then
PID=$(cat $PIDFILE)
ps -p $PID > /dev/null 2>&1
if [ $? -eq 0 ] ; then
log_info "script already running with PID $PID"
exit 0
else
log_info "PID file is there but script is not running, clean-up $PIDFILE"
rm -f $PIDFILE
fi
fi
echo $$ > $PIDFILE
if [ $? -ne 0 ] ; then
log_error "Could not create PID file"
exit 1
fi
log_info "Create $PIDFILE with value $$"
str=$( pcp_node_info -h $DELEGATE_IP -p 9898 -w $PGP_NODE_ID )
if [ $? -ne 0 ] ; then
log_error "pgpool cannot be accessed"
rm -f $PIDFILE
exit 1
fi
read node port status weight status_name role date_status time_status <<< $str
if [ $status -ne $PGP_STATUS_DOWN ] ; then
log_info "pgpool status for node $node is $status_name and role $role, nothing to do"
rm -f $PIDFILE
exit 0
fi
log_info "Node $node is down (role is $role)"
# status down, the node is detached
# get the primary from pool_nodes
psql -h $DELEGATE_IP -p 9999 -U repmgr -c "show pool_nodes;" > /tmp/pool_nodes.log
if [ $? -ne 0 ] ; then
log_error "cannot connect to postgres via pgpool"
rm -f $PIDFILE
exit 1
fi
PRIMARY_NODE_ID=$( cat /tmp/pool_nodes.log | grep primary | grep -v down | cut -f1 -d"|" | sed -e "s/ //g")
PRIMARY_HOST=$( cat /tmp/pool_nodes.log | grep primary | grep -v down | cut -f2 -d"|" | sed -e "s/ //g")
log_info "Primary node is $PRIMARY_HOST"
# check if this node is a failed master (degenerated master)
# if yes then pcp_recovery_node or node rejoin is needed
if [ $role == "primary" ] ; then
# this should never happen !!
log_info "This node is a primary and it is down: recovery needed"
# sanity check
if [ $PRIMARY_NODE_ID -ne $PGP_NODE_ID ] ; then
log_error "Unpextected state, this node $PGP_NODE_ID is a primary according to pcp_node_info but pool_nodes said $PRIMARY_NODE_ID is master"
rm -f $PIDFILE
exit 1
fi
if [ "$_arg_auto_recover_primary" == "on" ] ; then
recover_failed_master "primary node reported as down in pgpool"
ret=$?
rm -f $PIDFILE
exit $ret
else
log_info "auto_recover_primary is off, do nothing"
rm -f $PIDFILE
exit 0
fi
fi
log_info "This node is a standby and it is down: check if it can be re-attached"
log_info "Check if the DB is running, if not do not start it but exit with error"
pg_ctl status
if [ $? -ne 0 ] ; then
log_error "the DB is not running"
rm -f $PIDFILE
exit 1
fi
check_is_streaming_from $PRIMARY_HOST
res=$?
if [ $res -eq 1 ] ; then
recover_standby
ret=$?
rm -f $PIDFILE
exit $ret
fi
if [ "$_arg_auto_recover_primary" == "on" ] ; then
log_info "node is standby in pgpool but it is not streaming from the primary, probably a degenerated master. Lets do pcp_recovery_node"
recover_failed_master "standby node not streaming from the primary"
ret=$?
rm -f $PIDFILE
exit $ret
else
log_info "node is supposed to be a standby but it is not streaming from the primary, however auto_recovery_primary is off so do nothing"
fi
rm -f $PIDFILE
exit 0
pgpool graphical interface
I developed a web based application on top of pgpool and postgres in order to visualize the cluster (state of the watchdog and state of the replication). For now the easiest way to use it is to clone the repo from github, build a docker image containing the app and then run the docker image either on one of the node or on another server (it needs access to the posgres servers via ssh)
I will go through the process to build the docker image and start it on my host. Note that depending on how you install docker (from docker-ce or from centos), you might have to use sudo to run docker commands as non-root user. Note that it requires a version of docker that supports multi-stage build, so go for docker-ce https://docs.docker.com/install/linux/docker-ce/centos/
# clone the github project
git clone git@github.com:saule1508/pgcluster.git
# get into the directory containing the app
cd pgcluster/manager
# get into the build directory
cd build
# NB: the user must be in the group docker, otherwise you need to add a sudo in front of the docker commands
# in the script build.bash
./build.bash
At the end of the script a docker image should be created, it should say “Successfully tagged manager:
The container needs an environment variable PG_BACKEND_NODE_LIST which is a csv list of the backends. It also needs the password for the user repmgr. So in this case:
PG_BACKEND_NODE_LIST: 0:pg01.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,1:pg02.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,2:pg03.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER
REPMGRPWD: rep123
the docker container should also be capable to connect to the 3 postgres nodes via ssh, without a password: to make this possible we will need to copy over the public key stored in the image to the 3 servers (the public key must be added to /root/.ssh/authorized_keys on the backends, we can use ssh-copy-id for that)
start the container, in order to copy the public key
docker run -ti --net host --entrypoint bash manager:0.8.0
# now we are inside the container, check that you can ping the backends
ping pg01.localnet
ping pg02.localnet
ping pg03.localnet
# copy the public key
ssh-copy-id postgres@pg01.localnet
ssh-copy-id postgres@pg02.localnet
ssh-copy-id postgres@pg03.localnet
# exit the container
exit
The tool executes a script called /opt/postgres/scripts/checks.sh on the backend, so we must install it on the 3 servers
#!/bin/bash
repmgr node check | grep -v "^Node" | while read line
do
ck=$(echo $line | sed -e "s/\t//" -e "s/ /_/g" | cut -f1 -d":")
res=$(echo $line | cut -f2- -d":")
echo repmgr,$ck,$res
done
df -k ${PGDATA} | grep -v "^Filesystem" | awk '{print "disk,"$NF","$5","$2","$3}'
df -k /backup | grep -v "^Filesystem" | awk '{print "disk,"$NF","$5","$2","$3}'
df -k /archive | grep -v "^Filesystem" | awk '{print "disk,"$NF","$5","$2","$3}'
And now we can run the container. It will expose the port 8080, so we must open this port on the firewall
firewall-cmd --add-port 8080/tcp --permanent
systemctl restart firewalld
systemctl restart docker
docker run -d --net host \
-v /var/run/docker.sock:/var/run/docker.sock \
-e PG_BACKEND_NODE_LIST=0:pg01.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,1:pg02.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER,2:pg03.localnet:5432:1:/u01/pg11/data:ALLOW_TO_FAILOVER \
-e REPMGRPWD:rep123 \
-e DBHOST=192.168.122.99 \
-e SCRIPTSDIR=/opt/postgres/scripts -e SSHPORT=22 -e BACKUPDIR=/u02/backup \
--name pgpoolmanager manager:0.8.0